在完成 冒險地圖功能 並部署上線後,我立刻讓自己的孩子開始試用平台。
雖然原本設計了 完成任務可以蒐集拼圖碎片、解鎖動物 的機制,孩子確實很喜歡,但我總覺得還有空間可以加入更多輔助學習的功能。
剛好最近孩子有在看成語故事書,我就想說乾脆將 成語學習 導入平台吧!
最初的構思是設計一個專門的成語學習頁面,讓孩子能自主在上面閱讀和學習。
不過想了想,這種被動的方式似乎很難讓孩子每天主動打開來用,效果可能有限。
於是,我開始與 AI 討論如何設計,才能既激起孩子的興趣,又兼顧良好的學習成效。
AI 建議我採用 「挑戰答題」 的形式,並且設定每日挑戰的條件限制。這樣:
最終我決定將挑戰與平台的 主線任務 結合:
AI 也提醒我,出題可以 根據已解鎖的成語 來進行,這樣每天的挑戰不僅能引入新知識,還能持續複習,形成漸進式學習循環。
既然平台的主題是 動物探險,成語自然也要呼應這個設定,所以我請 ChatGPT 幫忙生成大量與動物相關的成語及解釋。
原本打算一次產生 200 筆資料,但實測後發現會遇到不少問題:
AI 的回答是,目前 AI 在處理 一次性大量產出且需高度正確的結構化資料 時,主要有三個挑戰:
知識來源零散
AI 的知識來自書籍、網站、辭典、論文等多種來源,但這些資訊是分散的片段,並不是現成、完整且經過整理的「200 筆動物成語辭典」。
長程一致性難維持
單筆生成時可以逐一檢查,但一次要生成 200 筆,就必須同時確保:
這對 AI 來說屬於「長程一致性」問題,生成過程中容易發生遺漏、重複、或格式不統一。
列表越長,錯誤越容易累積
即使只有 1% 的錯誤率,生成 200 筆也可能出現 2 筆錯誤;而且這些錯誤可能是隱性的,例如故事細節與實際出處不符,需要人工或外部資料驗證才能發現。
後來我改用分批的方式:
雖然多花一些時間,但資料品質明顯提升,也方便後續統一存成 JSON 格式,直接匯入系統中。
[
{
"成語": "畫蛇添足",
"解釋": "原本畫好的蛇再加上腳,比喻做了多餘的事反而不好。",
"典故": "古代寓言中,一隻狐狸被老虎抓住了。狐狸對老虎說..."
}
]
之後有機會再研究怎樣用 AI 快速生成這種大量資料。對於教育性質應用來說,產生大量且正確的學習資料是非常常見的需求。

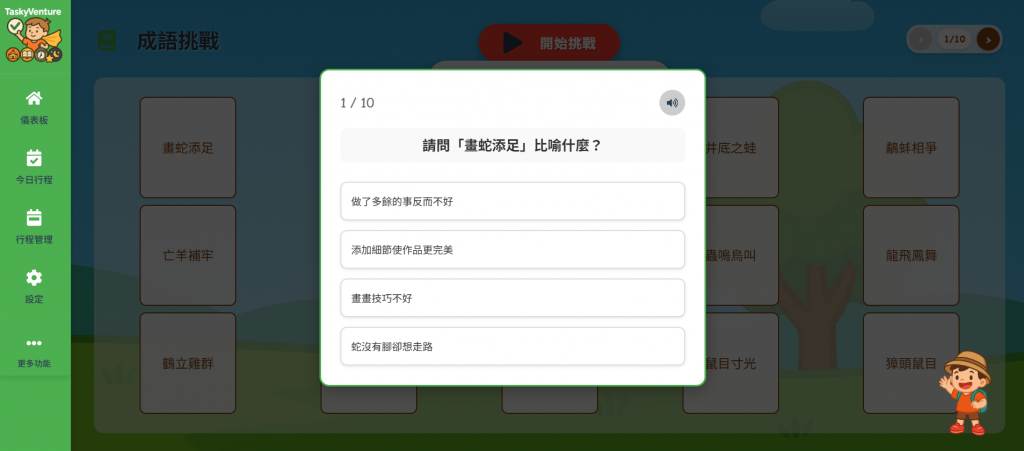
有了資料後,接下來就是頁面設計,我需要在左側欄新增「成語挑戰」分頁,按下後跳轉到成語挑戰頁面,並根據 JSON 內容列出成語按鈕。
下了提示詞後,AI 很快就產出了能直接運行的程式碼。
但實際測試時發現,顯示所有成語成一份列表,會造成載入過慢,而且可能造成部分裝置顯示不全。
最後我請 AI 改成 分頁顯示 來解決:
因為平台先前已經開發了:
所以在實作成語挑戰時,其實可以直接複用現有架構。
例如:
請參考「今日行程」頁面的動物問答功能
幫我改成成語挑戰版本
設計連續答對十題即可解鎖新成語
AI 很快完成初版程式碼,我再根據資料庫結構,讓 AI 幫忙設計每天剩餘挑戰次數、通關狀態、已解鎖成語數量等等資料紀錄。
測試時,可以直接打開 Firebase Console 即時觀察:
在完成功能測試後,我在「今日行程」頁面加入了一個貼心的小提示:
當孩子完成當天主線任務後,會跳出提醒「可以進行成語挑戰」。
這個細節改變了孩子的參與方式。
挑戰不再是冷冰冰的選項,而成了每天完成主線後的獎勵時刻。
整個成語挑戰功能,就像是平台拼圖上的第二塊學習碎片。
它讓知識不再孤立存在,而是與冒險地圖、任務解鎖、星星獎勵緊密連結。
希望能讓孩子在遊戲中自然地複習與吸收,不知不覺就把成語牢牢記住。
敬請期待下一篇:《成就抽獎系統:讓孩子在期待中培養堅持的力量》


 iThome鐵人賽
iThome鐵人賽